转自: http://blog.csdn.net/datascientist/article/details/7184248
最近研究云存储相关的系统,Oceanstore和Cassandra都用到了SEDA编程模型。
(注:关于Cassandra的代码结构和SEDA模型的使用情况可以参考这篇文章http://prettyprint.me/2010/05/02/understanding-cassandra-code-base/,里面还有一张时间序列图来说明程序的流程。)
Staged Event Driven Architecture (SEDA) 是加州大学伯克利分校研究的一套优秀的高性能互联网服务器架构模型。其设计目标是:支持大规模并发处理、简化系统开发、支持处理监测、支持系统资源管理。它的核心思想是把一个请求处理过程分成几个Stage,不同资源消耗的Stage使用不同数量的线程来处理,Stage间使用事件驱动的异步通信模式。http://www.eecs.harvard.edu/~mdw/papers/seda-sosp01.pdf这篇文章是介绍SEDA最好的材料。
传统的高性能服务器处理模型无非就是两种:多线程处理模型和事件驱动处理模型。关于这两种模型网上有很多资料了。http://www.iteye.com/topic/432134这篇文章把多线程模型和SEDA模型的实验对比以数字的形式展现出来了。而且详细描述了为什么多线程模型在某些场合不适用。简单理解就是传统多线程模型有的时候由于处理逻辑不同的线程对资源的需求不同,会导致有些CPU空闲,而另外一些CPU却浪费了大量的时间在线程的调度上,资源利用率不高。本质原因就是不同线程的处理逻辑对资源的需求不同。
SEDA模型处理的流程是:一个请求被分成多个stage处理,每一个stage各做各的,一个请求的多个stage可以串行化也可以并行化。stage外部使用Event-Driven,新到的请求放到event queue中,整个SEDA框架从该Stage对应的thread pool中的挑选一个线程运行Event Handler来处理事件,Event Handler处理完后将请求派发到下一个stage。下面是一个基于SEDA的处理流程:

对于SEDA中的每一个stage,它由上面的三部分构成:
1) 输入的event queue。SEDA中的event queue是限定大小的,代码里是通过链表来实现的。所以如果event queue的大小到达阈值,新到的event会被拒绝或转发到特定的stage。
2)thread pool:这个线程池对应用是通明的,并且每个stage的线程池是相互独立的。针对请求量及特点,线程池可以静态的调节,不至于某个stage的线程池耗尽所有的资源。
3)event handler,event handler接受event,做详细的用户指定的逻辑处理后将event分发到其余stage。event handler需要应用开发者编写。
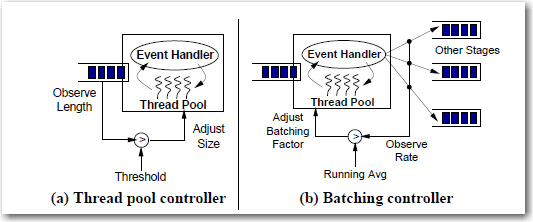
针对各个stage运行时的状态,SEDA引入resource controller来调解stage的资源分派和调节参数等。焦点的两个Controller是thread pool controller和batching controller。thread pool controller用来控制threadpool的运转时大小,比如当event queue很大时,就多分配些线程,反之则减少线程数。batching controller用来节制event handler同时处理的event的并发量(batching
factor),当batching factor增大时,增长了吞吐量但event均匀相应时间会变长,当batching factor变小时,环境相同。batching controller的控制结果使得batching factor的高低动摇来控制吞吐量和响合时间。这两个controller类似操作系统里进程调度的原则,在延迟和吞吐量中选择平衡。
下面是http://www.eecs.harvard.edu/~mdw/papers/seda-sosp01.pdf这个文章中介绍的一个机遇SEDA的HTTP的实现。整个请求的过程分为以下几个Stage: Socket listen,Socket read, HttpParse, PageCache, CacheMiss, file I/O, HttpSend, Socket
write等,不同stage有不同的thread pool和controller,并配置不同的参数,各个stage之间通过Event queue来传递消息。下一篇文章我将从源代码的角度分析这个HTTP服务器。

目前EMC的Atmos产品和Google的产品中都有用到SEDA。而国内互联网企业由于实际工程应用中往往开发效率和运行效率要综合考虑。而SEDA的开发效率相对较低,所以现在看国内各厂高负载高并发系统开发还是传统多线程占主导。
PS:http://matt-welsh.blogspot.com/2010/07/retrospective-on-seda.html
这是SEDA的作者最近对这个系统的回顾中反思了他当初设计系统的得失。(需要)
A Retrospective on SEDA
转自: http://blog.csdn.net/datascientist/article/details/7184248
最近研究云存储相关的系统,Oceanstore和Cassandra都用到了SEDA编程模型。
(注:关于Cassandra的代码结构和SEDA模型的使用情况可以参考这篇文章http://prettyprint.me/2010/05/02/understanding-cassandra-code-base/,里面还有一张时间序列图来说明程序的流程。)
Staged Event Driven Architecture (SEDA) 是加州大学伯克利分校研究的一套优秀的高性能互联网服务器架构模型。其设计目标是:支持大规模并发处理、简化系统开发、支持处理监测、支持系统资源管理。它的核心思想是把一个请求处理过程分成几个Stage,不同资源消耗的Stage使用不同数量的线程来处理,Stage间使用事件驱动的异步通信模式。http://www.eecs.harvard.edu/~mdw/papers/seda-sosp01.pdf这篇文章是介绍SEDA最好的材料。
传统的高性能服务器处理模型无非就是两种:多线程处理模型和事件驱动处理模型。关于这两种模型网上有很多资料了。http://www.iteye.com/topic/432134这篇文章把多线程模型和SEDA模型的实验对比以数字的形式展现出来了。而且详细描述了为什么多线程模型在某些场合不适用。简单理解就是传统多线程模型有的时候由于处理逻辑不同的线程对资源的需求不同,会导致有些CPU空闲,而另外一些CPU却浪费了大量的时间在线程的调度上,资源利用率不高。本质原因就是不同线程的处理逻辑对资源的需求不同。
SEDA模型处理的流程是:一个请求被分成多个stage处理,每一个stage各做各的,一个请求的多个stage可以串行化也可以并行化。stage外部使用Event-Driven,新到的请求放到event queue中,整个SEDA框架从该Stage对应的thread pool中的挑选一个线程运行Event Handler来处理事件,Event Handler处理完后将请求派发到下一个stage。下面是一个基于SEDA的处理流程:
对于SEDA中的每一个stage,它由上面的三部分构成:
1) 输入的event queue。SEDA中的event queue是限定大小的,代码里是通过链表来实现的。所以如果event queue的大小到达阈值,新到的event会被拒绝或转发到特定的stage。
2)thread pool:这个线程池对应用是通明的,并且每个stage的线程池是相互独立的。针对请求量及特点,线程池可以静态的调节,不至于某个stage的线程池耗尽所有的资源。
3)event handler,event handler接受event,做详细的用户指定的逻辑处理后将event分发到其余stage。event handler需要应用开发者编写。
针对各个stage运行时的状态,SEDA引入resource controller来调解stage的资源分派和调节参数等。焦点的两个Controller是thread pool controller和batching controller。thread pool controller用来控制threadpool的运转时大小,比如当event queue很大时,就多分配些线程,反之则减少线程数。batching controller用来节制event handler同时处理的event的并发量(batching
factor),当batching factor增大时,增长了吞吐量但event均匀相应时间会变长,当batching factor变小时,环境相同。batching controller的控制结果使得batching factor的高低动摇来控制吞吐量和响合时间。这两个controller类似操作系统里进程调度的原则,在延迟和吞吐量中选择平衡。
下面是http://www.eecs.harvard.edu/~mdw/papers/seda-sosp01.pdf这个文章中介绍的一个机遇SEDA的HTTP的实现。整个请求的过程分为以下几个Stage: Socket listen,Socket read, HttpParse, PageCache, CacheMiss, file I/O, HttpSend, Socket
write等,不同stage有不同的thread pool和controller,并配置不同的参数,各个stage之间通过Event queue来传递消息。下一篇文章我将从源代码的角度分析这个HTTP服务器。
目前EMC的Atmos产品和Google的产品中都有用到SEDA。而国内互联网企业由于实际工程应用中往往开发效率和运行效率要综合考虑。而SEDA的开发效率相对较低,所以现在看国内各厂高负载高并发系统开发还是传统多线程占主导。
PS:http://matt-welsh.blogspot.com/2010/07/retrospective-on-seda.html
这是SEDA的作者最近对这个系统的回顾中反思了他当初设计系统的得失。(需要)
A Retrospective on SEDA
分享到:




相关推荐
Staged Event Driven Architecture (SEDA) 是加州大学伯克利分校研究的一套优秀的高性能互联网服务器架构模型
Staged Event Driven Architecture (SEDA) 是加州大学伯克利分校研究的一套优秀的高性能互联网服务器架构模型
【大纲】 服务端软件=排队服务 回顾常见的并发模型 介绍SEDA 分享我们的经验
NULL 博文链接:https://xylong.iteye.com/blog/1441956
SEDA(StagedEvent-DrivenArchitectrue)--兼谈服务器体系结构设计一.引言
we call the staged event-driven architecture (SEDA). SEDA is intended to support massive concurrency demands and simplify the construc- tion of well-conditioned services. In SEDA, applications consist...
基于SEDA架构的网格服务容器设计与实现.pdf
采用分级事件驱动架构SEDA(Staged Event Driven Architecture),通过划分阶段Stage的方式解除耦合,在阶段之间采用事件进行异步消息通信,结合非阻塞的I/O机制设计实现了一个事件驱动的网格服务容器,并从吞吐量、...
基于SEDA的企业服务总线的设计与设计,清晰地讲解了SEDA的结构与设计原理,为高并发网络响应提供了一种实现思路
有关 ehensin-seda 的最新信息,请访问我们的网站:
阶段事件驱动架构设计论文,详细介绍了seda的架构体系。
seda过载保护
1、安装环境 2、安装依赖软件 3、安装配置Seda 4、测试seda能否正常工作
NULL 博文链接:https://ailikes.iteye.com/blog/2233024
基于SEDA的企业服务总线的设计与实现,基于SEDA的企业服务总线的设计与实现
mule & seda 学习二.docx
SEDA: An Architecture for Scalable,Well-Conditioned Internet ServicesMatt Welsh, David Culler, and Eric BrewerUC Berkeley Computer Science Division mdw@cs.berkeley.eduhttp://www.cs.berkeley.edu/~mdw/...
针对Web服务集成过程中分阶段事件驱动架构(SEDA)仅考虑服务集成架构的资源消耗,而对被集成的服务及由其构成的任务资源耗费考虑不足的问题,提出了分阶段优先级事件驱动架构(SPEDA).选取评价指标,通过熵权法对事件...
Aggregate Framework概述 Aggregate Framework是基于DDD和CQRS思想而开发的一个领域驱动框架。其主要目标是方便开发人员运用DDD和CQRS思想来构建复杂的、可扩展的应用系统。该框架提供了最核心的构建块的实现,比如...
事件驱动处理框架通过两种方式改善了线程体系结构的性能:(1)事件处理程序通常比线程解决方案具有更低的内存和上下文切换开销;(2)事件驱动系统允许应用程序分配和监视计算和I / O以极其细粒度的方式使用资源。...